HỌC ORACLE DATABASE CƠ BẢN TỪ A-Z - BÀI 2: CÁC THÀNH PHẦN KIẾN TRÚC ORACLE DATABASE A-Z
Oracle server là một hệ thống quản trị cơ sở dữ liệu đối tượng-quan hệ cho phép quản lý thông tin một cách toàn diện. Oracle server bao gồm hai thành phần chính là Oracle instance và Oracle database
NỘI DUNG:
2.1. KIẾN TRÚC ORACLE SERVER
2.1.1. ORACLE INSTANCE
Cấu trúc bộ nhớ (SGA, PGA) Cấu trúc tiến trình
2.1.2. Oracle database - Cấu trúc lưu trữ
Cấu trúc vật lý database
Cấu trúc logic databse
2.1.3. Quản trị cơ sở dữ liệu Oracle
2.1.4. Thiết lập các tham số khởi tạo ảnh hưởng tới kích cỡ bộ nhớ SGA
2.2. KẾT NỐI TỚI ORACLE SERVER
2.2.1. Mô hình kết nối
2.2.2. Một số khái niệm cơ bản liên quan đến kết nối
2.2.3. Kết nối tới database
2.3. Áp dụng kiến trúc Cơ sở dữ liệu Oracle để hiểu hoạt động SELECT, INSERT, UPDATE, DELETE
Chi tiết bài viết:
2.1. KIẾN TRÚC ORACLE SERVER
Oracle
server là một hệ thống quản trị cơ sở dữ liệu đối tượng-quan hệ cho phép quản
lý thông tin một cách toàn diện. Oracle
server bao gồm hai thành phần chính là Oracle instance và Oracle database.
2.1.1. Oracle
Instance
Oracle instance bao gồm một Cấu trúc bộ nhớ (System Global Area (SGA) và Program Global Area (PGA) được sử dụng để quản trị cơ sở dữ liệu, bộ nhớ lưu mã chương trình đang chạy, dữ liệu chia sẻ cho các user (shared pool, buffer cache, UGA) và dữ liệu riêng cho mỗi user kết nối đến) và Cấu trúc tiến trình. Oracle instance được xác định qua tham số môi trường ORACLE_SID của hệ điều hành.
Cấu trúc bộ nhớ
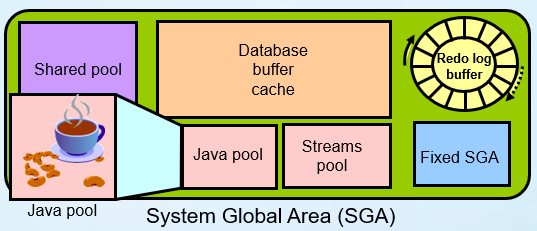
Hình vẽ 1.Kiến trúc Oracle Server
System Global Area - SGA
SGA
là vùng bộ nhớ chia sẻ được sử dụng để lưu trữ dữ liệu và các thông tin điều
khiển của Oracle server. SGA được cấp phát (allocated) trong bộ nhớ của máy
tính mà Oracle server đang hoạt động trên đó. Các User kết nối tới Oracle sẽ
chia sẻ các dữ liệu có trong SGA, việc mở rộng không gian bộ nhớ cho SGA sẽ làm
nâng cao hiệu suất của hệ thống, lưu trữ được nhiều dữ liệu trong hệ thống hơn
đồng thời giảm thiểu các thao tác truy xuất đĩa (disk I/O).
SGA
bao gồm một vài cấu trúc bộ nhớ chính:
§Shared
pool: Là một phần của SGA lưu các cấu trúc bộ nhớ chia sẻ.
§Database
buffer cache: Lưu trữ các dữ liệu được sử dụng gần nhất.
§Redo
log buffer: Được sử dụng cho việc dò tìm lại các thay đồi trong cơ sở dữ liệu
và được thực hiện bởi các background process.
Để chi tiết hơn, ta sẽ xem xét cụ thể từng thành phần.
Share
Pool
Shared
pool là một phần trong SGA và được sử dụng khi thực hiện phân tích câu lệnh
(parse phase). Kích thước của Shared pool được xác định bởi tham số SHARED_POOL_SIZE
có trong parameter file (file tham số).
Các
thành phần của Shared pool gồm có: Library cache và Data dictionary cache.
Hình vẽ 2.Cấu trúc Share Pool
Library
Cache
Library
cache lưu trữ thông tin về các câu lệnh SQL được sử dụng gần nhất bao gồm:
§Nội
dung của câu lệnh dạng text (văn bản).
§Parse
tree (cây phân tích) được xây dựng tuỳ thuộc vào câu lệnh.
§Execution
plan (sơ đồ thực hiện lệnh) gồm các bước thực hiện và tối ưu lệnh.
Do
các thông tin trên đã được lưu trữ trong Library cache nên khi thực hiện lại một
câu lệnh truy vấn, trước khi thực hiện câu lệnh, Server process sẽ lấy lại các
thông tin đã được phân tích mà không phải phân tích lại câu lệnh. Do vậy,
Library cache có thể giúp nâng cao hiệu suất thực hiện lệnh.
Data
Dictionary Cache
Data
dictionary cache là một thành phần của Shared pool lưu trữ thông tin của dictionary cache được sử dụng gần
nhất như các định nghĩa các bảng, định nghĩa các cột, usernames, passwords, và
các privileges (quyền).
Trong giai đoạn
phân tích lệnh (parse phase), Server process sẽ tìm các thông tin trong
dictionary cache để xác định các đối tượng trong câu lệnh SQL và để xác định
các mức quyền tương ứng. Trong trường hợp cần thiết, Server process có thể khởi
tạo và nạp các thông tin từ các file dữ liệu.
Data
buffer cache
Khi
thực hiện một truy vấn, Server process sẽ tìm các blocks cần thiết trong
database buffer cache. Nếu không tìm thấy block trong database buffer cache,
Server process mới đọc các block từ data file và tạo luôn một bản sao của block
đó vào trong vùng nhớ đệm (buffer cache). Như vậy, với các lần truy xuất tới block
đó sau này sẽ không cần thiết phải truy xuất vào datafile nữa.
Hình vẽ 3.Database buffer cache
Database
buffer cache là vùng nhớ trong SGA sử dụng để lưu trữ các block dữ liệu được sử
dụng gần nhất. Tương tự như kích thước của blocks dữ liệu được xác định bởi tham
số DB_BLOCK_SIZE,
kích thước của vùng đệm trong buffer cache cũng được xác định bởi tham số DB_BLOCK_BUFFERS.
Oracle
server sử dụng giải thuật least recently used (LRU) algorithm để làm tươi lại
vùng nhớ. Theo đó, khi nạp mới một block vào bộ đệm, trong trường hợp bộ đệm đã
đầy, Oracle server sẽ loại bớt block ít được sử dụng nhất ra khỏi bộ đệm để nạp
block mới vào bộ đệm.
Redo
log buffer
Server
process ghi lại các thay đổi của một instance vào redo log buffer, đây cũng là
một phần bộ nhớ SGA.
Hình vẽ 4.Redo log buffer
Có
một số đặc điểm cần quan tâm của Redo log buffer:
§Kích
thước được xác định bởi tham số LOG_BUFFER.
§Lưu trữ
các redo records (bản ghi hồi phục) mỗi khi có thay đổi dữ liệu.
§Redo
log buffer được sử dụng một cách thường xuyên và các thay đổi bởi một
transaction có thể nằm đan xen với các thay đổi của các transactions khác.
§Bộ đệm
được tổ chức theo kiểu circular buffer (bộ đệm nối vòng) tức là dữ liệu thay đổi
sẽ tiếp tục được nạp lên đầu sau khi vùng đệm đã được sử dụng hết.
Large Pool
Sử dụng cho:
§Bộ nhớ của session cho shared server và giao diện Oracle XA
§Tiến trình server liên quan đến I/O
§Hoạt động backup and restore CSDL
Java Pool
Vùng nhớ Java pool được sử dụng cho các đoạn Java code và dữ liệu trong JVM của các session xác định trước đó
Program Global Area - PGA
Trong Oracle Database, PGA (Program Global Area) là một khu vực bộ nhớ đặc biệt được sử dụng bởi mỗi tiến trình (process) của hệ thống database. PGA có tác dụng chứa các cấu trúc dữ liệu và thông tin cần thiết cho việc thực thi các câu lệnh SQL và các hoạt động liên quan.
Các tác dụng chính của PGA trong Oracle Database bao gồm:
Quản lý bộ nhớ: PGA giúp quản lý bộ nhớ cho mỗi tiến trình, bao gồm bộ nhớ cho các vùng cấu trúc dữ liệu như Sorting Area (vùng sắp xếp như ORDER BY, GROUP BY), Hash Area (vùng băm), và Bitmap Merge Area (vùng ghép bitmap), giúp tăng hiệu suất thực thi câu lệnh SQL.
Lưu trữ dữ liệu tạm thời: PGA cũng được sử dụng để lưu trữ các dữ liệu tạm thời trong quá trình thực thi câu lệnh SQL, chẳng hạn như kết quả của các phép sắp xếp, kết quả của các phép toán băm, và các dữ liệu tạm thời khác.
Quản lý các biến môi trường: PGA cung cấp không gian để lưu trữ các biến môi trường như biến số, tham số và các giá trị tạm thời khác trong quá trình thực thi các câu lệnh SQL.
Quản lý vùng stack: PGA quản lý vùng stack cho mỗi quy trình, trong đó lưu trữ các thông tin quan trọng như địa chỉ của các khối mã, các biến cục bộ và thông tin về trạng thái của quy trình.
Tóm lại, PGA trong Oracle Database có vai trò quan trọng trong việc quản lý bộ nhớ, lưu trữ dữ liệu tạm thời và các biến môi trường, giúp cải thiện hiệu suất và độ tin cậy của hệ thống.
Cấu trúc tiến trình
Tiến trình User
- Là ứng dụng hoặc công cụ (TOAD, SQL Navigator,..) kết nối tới CSDL Oracle
Tiến trình Database
- Tiến trình Server: Kết nối tới Oracle instance và được bắt đầu khi một user thiết lập một session
- Tiến trình Background: Được bật cùng khi Oracle instance được bật.
Tiến trình Daemon / Application
- Listener mạng
- Grid Infrastructure daemon
Background
process (các tiến trình nền) thực hiện các chức năng thay cho lời gọi tiến
trình xử lý tương ứng. Nó điều khiển vào ra, cung cấp các cơ chế xử lý song
song nâng cao hiệu quả và độ tin cậy. Tùy theo từng cấu hình mà Oracle instance
có các Background process tiêu biểu như:
§Database
Writer (DBW0):
Ghi lại các thay đổi trong data buffer cache ra các file dữ liệu.
§Log
Writer (LGWR):
Ghi lại các thay đổi được đăng ký trong redo log buffer vào các redo log files.
§System
Monitor (SMON):
Kiểm tra sự nhất quán trong database.
§Process
Monitor (PMON):
Dọn dẹp lại tài nguyên khi các tiến trình của Oracle gặp lỗi.
§Checkpoint
Process (CKPT):
Cập nhật lại trạng thái của thông tin trong file điều khiển (control file) và
file dữ liệu (datafile) mỗi khi có thay đổi trong buffer cache.
Database Writer
(DBW0)
Server
process ghi lại các dữ liệu thay đổi để rollback và dữ liệu của các block trong
buffer
cache.
Database writer (DBWR) ghi các thông
tin được đánh dấu thay đổi từ database buffer cache lên các data files nhằm đảm
bảo luôn có khoảng trống bộ đệm cần thiết cho việc sử dụng.
Hình vẽ 5.Database Writer (DBWR)
Với
việc sử dụng này, hiệu suất sử dụng database sẽ được cải thiện do Server
processes chỉ tạo các thay đổi trên buffer cache, DBWR ghi dữ liệu vào
các data file cho tới khi:
§Số lượng
buffers đánh bị dấu đạt tới giá trị ngưỡng.
§Tiến
trình duyệt tất cả buffer mà vẫn không tìm thấy dữ liệu tương ứng.
§Quá thời
gian quy định.
Log Writer
Log
Writer (LGWR) là một trong các
background process có trách nhiệm quản lý redo log buffer để ghi lại các thông
tin trong Redo log buffer vào Redo log file. Redo log buffer là bộ đệm dữ liệu
được tổ chức theo kiểu nối vòng.
Hình vẽ 6.Log Writer (LGWT)
LGWR ghi lại dữ liệu một cách tuần tự
vào redo log file theo các tình huống sau:
§Khi
redo log buffer đầy
§Khi xảy
ra timeout (thông thường là 3 giây)
§Trước
khi DBWR ghi lại các blocks bị
thay đổi trong data buffer cache vào các data files.
§Khi
commit một transaction.
System Monitor
(SMON)
Tiến
trìnhsystem monitor (SMON) thực hiện
phục hồi các sự cố (crash recovery) ngay tại thời điểm instance được khởi động
(startup), nếu cần thiết. SMON cũng có trách
nhiệm dọn dẹp các temporary segments không còn được sử dụng nữa trong
dictionary-managed tablespaces. SMON
khôi phục lại các transactions bị chết mỗi khi xảy ra sự cố. SMON
đều đặn thực hiện kiểm tra và khắc phục các sự cố khi cần.
Trong
môi trường Oracle Parallel Server, SMON
process của một instance có thể thực hiện khôi phục instance trong trường hợp
instance hay CPU của máy tính đó gặp sự cố.
Process Monitor
(PMON)
Tiến
trình process monitor (PMON)
thực hiện tiến trình phục hồi mỗi khi có một user process gặp lỗi. PMON
có trách nhiệm dọn dẹp database buffer cache và giải phóng tài nguyên mà user
process đó sử dụng. Ví dụ, nó thiết lập lại (reset) trạng thái của các bảng
đang thực hiện trong transaction, giải phóng các locks trên bảng này, và huỷ bỏ process ID của nó ra khỏi danh sách
các active processes.
PMON kiểm tra trạng thái của nơi gửi
(dispatcher ) và các server processes, khởi động lại (restarts) mỗi khi xảy ra
sự cố. PMON cũng còn thực hiện việc
đăng ký các thông tin về instance và dispatcher processes với network listener.
Tương
tự như SMON, PMON
được gọi đến mỗi khi xảy ra sự cố trong hệ thống.
Checkpoint Process
(CKPT)
Cập
nhật lại trạng thái của thông tin trong file điều khiển và file dữ liệu mỗi khi
có thay đổi trong buffer cache. Xảy ra checkpoints khi:
§Tất cả
các dữ liệu trong database buffers đã bị thay đổi tính cho đến thời điểm
checkpointed sẽ được background process DBWRn ghi lên data files.
§Background
process CKPT cập nhật phần headers của các data files và các control files.
Checkpoints
có thể xảy ra đối với tất cả các data files trong database hoặc cũng có thể xảy
ra với một data files cụ thể.
Checkpoint
xảy ra theo các tình huống sau:
§Mỗi khi
có log switch
§Khi một
shut down một database với các chế độ trừ chế độ abort
§Xảy ra
theo như thời gian quy định trong các tham số khởi tạo LOG_CHECKPOINT_INTERVAL (tính theo block OS, default 0) và LOG_CHECKPOINT_TIMEOUT (tinsht heo thời gian, default 1800s). Nếu FAST_START_MTTR_TARGET (tham số này xác định thời gian để phục hồi crash revoery) được thiết lập thì LOG_CHECKPOINT_INTERVAL bị ghi đè, để dùng tham số này thì phải disable tham số LOG_CHECKPOINT_TIMEOUT về 0.
§Khi có
yêu cầu trực tiếp của quản trị viên (alter system switch logfile/checkpoint)
Thông
tin về checkpoint được lưu trữ trong Alert file trong trường hợp các tham số khởi
tạo LOG_CHECKPOINTS_TO_ALERT
được đặt là TRUE.
Và ngược lại với giá trị FALSE.
2.1.2. Oracle
database
Oracle
database là tập hợp các dữ liệu được xem như một đơn vị thành phần
(Unit). Database có nhiệm vụ lưu trữ và trả về các thông tin liên quan.
Database được xem xét dưới hai góc độ cấu trúc logic và cấu trúc vật
lý . Tuy vậy, hai cấu trúc dữ liệu này vẫn tồn tại tách biệt nhau, việc quản
lý dữ liệu theo cấu trúc lưu trữ vật lý không gây ảnh hưởng tới cấu trúc logic
Oracle
database được xác định bởi tên một tên duy nhất và được quy định trong tham số
DB_NAME của parameter file.
Hình vẽ 7.Cấu trúc database
Cấu trúc vật lý database
Cấu
trúc vật lý bao gồm tập hợp các control file, online redo log file và các
datafile:
Datafiles
Mỗi một Oracle database đều có thể có một hay nhiều datafiles.
Các database datafiles chứa toàn bộ dữ liệu trong database. Các dữ liệu thuộc cấu
trúc logic của database như tables hay
indexes đều được lưu trữ dưới dạng vật lý trong các datafiles của database.
Một số tính chất của datafiles:
§Mỗi
datafile chỉ có thể được sử dụng trong một database.
§Bên cạnh
đó, datafiles cũng còn có một số tính chất cho phép tự động mở rộng kích thước
mỗi khi database hết chỗ lưu trữ dữ liệu.
§Một hay
nhiều datafiles tạo nên một đơn vị lưu trữ logic của database gọi là
tablespace.
§Một
datafile chỉ thuộc về một tablespace.
Dữ liệu trong một datafile có thể đọc
ra và lưu vào vùng nhớ bộ đệm của Oracle. Ví dụ: khi một user muốn truy cập dữ liệu
trong một table thuộc database. Trong trường hợp thông tin yêu cầu không có
trong cache memory hiện thời, nó sẽ được đọc trực tiếp từ các datafiles ra và
lưu trữ vào trong bộ nhớ.
Tuy nhiên, việc bổ sung hay thêm mới dữ liệu vào
database không nhất thiết phải ghi ngay vào các datafile. Các dữ liệu có thể tạm
thời ghi vào bộ nhớ để giảm thiểu việc truy xuất tới bộ nhớ ngoài (ổ đĩa) làm
tăng hiệu năng sử dụng hệ thống. Công việc ghi dữ liệu này được thực hiện bởi
DBWn background process.
Redo Log Files
Mỗi Oracle database đều có một tập hợp từ 02 redo
log files trở lên. Các redo log files trong database thường được
gọi là database's redo log. Một redo log được tạo thành từ nhiều redo
entries (gọi là các redo records).
Chức năng chính của redo log là ghi lại tất cả các
thay đổi đối với dữ liệu trong database. Redo log files được sử
dụng để bảo vệ database khỏi những hỏng hóc do sự cố. Oracle cho phép sử dụng
cùng một lúc nhiều redo log gọi là multiplexed redo log để cùng lưu trữ
các bản sao của redo log trên các ổ đĩa khác nhau.
Các thông tin trong redo log file
chỉ được sử dụng để khôi phục lại database trong trường hợp hệ thống gặp sự cố
và không cho phép viết trực tiếp dữ liệu trong database lên các datafiles trong
database. Ví dụ: khi có sự cố xảy ra như mất điện bất chợt chẳng
hạn, các dữ liệu trong bộ nhớ không thể ghi trực tiếp lên các datafiles và gây
ra hiện tượng mất dữ liệu. Tuy nhiên, tất cả các dữ liệu bị mất này đều có thể
khôi phục lại ngay khi database được mở trở lại. Việc này có thể thực hiện được
thông qua việc sử dụng ngay chính các thông tin mới nhất có trong các redo log
files thuộc datafiles. Oracle sẽ khôi phục lại các database cho đến thời điểm
trước khi xảy ra sự cố.
Công việc khôi phục dữ liệu từ các redo log được gọi
là rolling forward.
Control Files
Mỗi Oracle database đều có ít nhất một control file.
Control file chứa các mục thông tin quy định cấu trúc vật lý của database như:
§Tên của
database.
§Tên và
nơi lưu trữ các datafiles hay redo log files.
§Time
stamp (mốc thời gian) tạo lập database, ...
Mỗi khi nào một
instance của Oracle database được mở, control file của nó sẽ được sử dụng để
xác định data files và các redo log files đi kèm. Khi các thành phần vật lý cả
database bị thay đổi (ví dụ như, tạo mới datafile hay redo log file), Control
file sẽ được tự động thay đổi tương ứng bởi Oracle.
Control file cũng được sử dụng đến khi thực hiện khôi
phục lại dữ liệu.
Cấu trúc logic databse
Cấu trúc logic của Oracle database bao gồm
các đối tượng tablespaces, schema objects, data blocks, extents, và segments.
Tablespaces
Một database có thể
được phân chia về mặt logic thành các đơn vị gọi là các tablespaces, Tablespaces thường bao gồm một nhóm các thành
phần có quan hệ logic với nhau.
Databases, Tablespaces, và Datafiles
Mối quan hệ giữa
các databases, tablespaces, và datafiles có thể được minh hoạ bởi hình vẽ sau:
Hình vẽ 8.Quan hệ giữa database, tablespace và
datafile
Có một số điểm ta
cần quan tâm:
§Mỗi
database có thể phân chia về mặt logic thành một hay nhiều tablespace.
§Mỗi
tablespace có thể được tạo nên, về mặt vật lý, bởi một hoặc nhiều datafiles.
§Kích
thước của một tablespace bằng tổng kích thước của các datafiles của nó. Ví dụ:
trong hình vẽ ở trên SYSTEM tablespace có kích thước là 2 MB còn USERS
tablespace có kích thước là 4 MB.
§Kích
thước của database cũng có thể xác định được bằng tổng kích thước của các
tablespaces của nó. Ví dụ: trong hình vẽ trên thì kích thước của database là 6
MB.
Schema
và Schema Objects
Schema là tập
hợp các đối tượng (objects) có trong database. Schema objects là các cấu
trúc logic cho phép tham chiếu trực tiếp
tới dữ liệu trong database. Schema objects bao gồm các cấu trúc như tables,
views, sequences, stored procedures, synonyms, indexes, clusters, và database
links.
Data
Blocks, Extents, and Segments
Oracle điểu khiển
không gian lưu trữ trên đĩa cứng theo các cấu trúc logic bao gồm các data blocks, extents, và
segments.
Oracle Data Blocks
Là mức phân cấp
logic thấp nhất, các dữ liệu của Oracle
database được lưu trữ trong các data blocks. Một data block tương ứng với
một số lượng nhất định các bytes vật lý của database trong không gian đĩa cứng.
Kích thước của một data block được chỉ ra cho mỗi Oracle database ngay khi
database được tạo lập. Database sử dụng, cấp phát và giải phóng vùng không gian
lưu trữ thông qua các Oracle data blocks.
Extents
Là mức phân chia
cao hơn về mặt logic các vùng không gian trong database. Một extent bao
gồm một số data blocks liên tiếp nhau, cùng được lưu trữ tại một thiết bị lưu
giữ. Extent được sử dụng để lưu trữ các thông tin có cùng kiểu.
Segments
Là mức phân chia cao hơn nữa về mặt
logic các vùng không gian trong
database. Một segment là một tập hợp các extents được cấp phát cho một cấu
trúc logic . Segment có thể được phân chia theo nhiều loại khác nhau:
Data segment
Mỗi một
non-clustered table có một data segment. Các dữ liệu trong một table được lưu
trữ trong các extents thuộc data segment đó. Với một partitioned table thì mỗi
each partition lại tương ứng với một data segment.
Mỗi Cluster
tương ứng với một data segment. Dữ liệu của tất cả các table trong cluster đó
đều được lưu trữ trong data segment thuộc Cluster đó.
index segment
Mỗi một index đều
có một index segment lưu trữ các dữ liệu của nó. Trong partitioned index thì
mỗi partition cũng lại tương ứng với một index segment.
rollback segment
Một hoặc nhiều
rollback segments của database được tạo lập bởi người quản trị database để
lưu trữ các dữ liệu trung gian phục vụ cho việc khôi phục dữ liệu.
Các thông tin
trong Rollback segment được sử dụng để:
§Tạo sự
đồng nhất các thông tin đọc được từ database
§Sử dụng
trong quá trình khôi phục dữ liệu
§Phục
hồi lại các giao dịch chưa commit đối với mỗi user
temporary
segment
Temporary
segments được tự động tạo bởi Oracle mỗi khi một câu lệnh SQL statement cần đến
một vùng nhớ trung gian để thực hiện các công việc của mình như sắp xếp dữ liệu.
Khi kết thúc câu lệnh đó, các extent thuộc temporary segment sẽ lại được hoàn
trả cho hệ thống.
Oracle thực hiện cấp
phát vùng không gian lưu trữ một cách linh hoạt mỗi khi các extents cấp phát đã
sử dụng hết.
Các
cấu trúc vật lý khác
Ngoài
ra, Oracle Server còn sử dụng các file khác để lưu trữ thông tin. Các file đó
bao gồm:
§Parameter
file: Parameter file chỉ ra các tham số được sử dụng trong database. Người quản
trị database có thể sửa đổi một vài thông tin có trong file này. Các tham số
trong parameter file được viết ở dạng văn bản.
§Password
file: Xác định quyền của từng user trong database. Cho phép người sử dụng khởi
động và tắt một Oracle instance.
§Archived
redo log files: Là bản off line của các redo log files chứa các thông tin cần
thiết để phục hồi dữ liệu.
2.1.3. Quản
trị cơ sở dữ liệu Oracle
Quản
trị cơ sở dữ liệu là công việc bảo trì và vận hành Oracle server để nó có thể
tiếp nhận và xử lý được tất cả các yêu cầu (requests) từ phía Client. Để làm được
điều này, người quản trị viên cơ sở dữ liệu cần phải hiểu được kiến trúc của
Oracle database.
2.1.4. Thiết
lập các tham số khởi tạo ảnh hưởng tới kích cỡ bộ nhớ SGA
Tham số khởi tạo ảnh hưởng tới kích thước
bộ nhớ cấp phát cho vùng System Global Area. Ngoại trừ tham số SGA_MAX_SIZE, còn lại các tham số khác đều là tham số động tức là
có thể thay đổi giá trị của chúng ngay trong lúc database đang chạy thông qua
câu lệnh ALTER SYSTEM. Kích thước của
SGA cũng có thể thay đổi được trong quá trình chạy database.
Thiết lập tham số
cho Buffer Cache
Tham số khởi tạo buffer cache quy định
kích thước của buffer cache là một phần của SGA. .
Ta sử dụng các tham số DB_CACHE_SIZE và một trong những tham số DB_nK_CACHE_SIZE để cho phép sử dụng chế độ multiple block
sizes đối với database. Oracle sẽ tự động gán các giá trị mặc định cho tham số
the DB_CACHE_SIZE, còn tham số DB_nK_CACHE_SIZE sẽ được gán mặc định bằng 0.
Kích thước của buffer cache sẽ có ảnh hưởng
nhiều tới hiệu suất thực hiện của hệ thống. Kích thước càng lớn thì càng giảm bớt
việc đọc và ghi đĩa. Tuy nhiên, kích thước của cache lớn sẽ tốn nhiều bộ nhớ và
sẽ có nhiều tốn kém trong việc thực hiện paging (phân trang) hay swapping (trao
đổi) bộ nhớ.
Tham số DB_CACHE_SIZE
Tham số khởi tạo DB_CACHE_SIZE được sử dụng thay thế cho tham số DB_BLOCK_BUFFERS của các phiên bản Oracle trước kia. Tham số DB_CACHE_SIZE quy định kích thước của block buffers chuẩn. Kích thước
của một block chuẩn lại được quy định trong tham số DB_BLOCK_SIZE.
Tuy vậy, tham số DB_BLOCK_BUFFERS vẫn được sử dụng để tương thích với các phiên bản trước,
tuy nhiên giá trị của nó không được sử dụng cho các tham số động.
Tham số DB_nK_CACHE_SIZE
Chỉ ra kích cỡ là bội số nguyên lần kích
thước của block buffers. Nó được chỉ ra bởi các tham số:
§DB_2K_CACHE_SIZE
§DB_4K_CACHE_SIZE
§DB_8K_CACHE_SIZE
§DB_16K_CACHE_SIZE
§DB_32K_CACHE_SIZE.
Mỗi
tham số chỉ ra kích cỡ của buffer cache tương ứng với kích cỡ của block.
Ví
dụ:
DB_BLOCK_SIZE=4096
DB_CACHE_SIZE=12M
DB_2K_CACHE_SIZE=8M
DB_8K_CACHE_SIZE=4M
Ở ví dụ này, các tham số chỉ ra kích thước
block chuẩn của database là 4K. Kích thước cache tương ứng với kích thước block
chuẩn là 12M. Các kích thước mở rộng của cache là 2K và 8K sẽ được đặt lại với
giá trị tương ứng là 8M và 4M.
Điều chỉnh kích cỡ
của Shared Pool
Tham số SHARED_POOL_SIZE trong phiên bản Oracle 11g là tham số động, tức là có thể thay đổi được
giá trị của nó (điều này không thể thực hiện được trong các phiên bản trước).
Nó cho phép ta thay đổi kích thước của shared pool là một trong các thành phần
của SGA. Theo mặc định Oracle cũng chọn một giá trị mặc định phù hợp cho tham số
này.
Điều chỉnh kích cỡ
của Large Pool
Tương tự như SHARED_POOL_SIZE,
tham số LARGE_POOL_SIZE cũng là một tham
số động, nó cho phép ta điều chỉnh kích cỡ của large pool, đây cũng là một
thành phần trong SGA. .
Giới hạn kích cỡ của SGA
Tham số SGA_MAX_SIZE quy định kích cỡ lớn nhất của System Global Area . Ta cũng có thể thay đổi kích cỡ của buffer caches, shared pool và large pool, tuy nhiên việc thay đổi này nên là mở rộng giá trị kích thước cho các thành phần của SGA. Giá trị mở rộng thêm này cũng không nên đặt tới ngưỡng của SGA_MAX_SIZE.
Trong trường hợp ta không chỉ rõ giá trị của SGA_MAX_SIZE thì Oracle sẽ tự động gán giá trị này bằng tổng số kích cỡ của các thành phần của SGA lúc ban đầu.
Ghi chú: Bạn chỉ cần đặt SGA, PGA hoặc Memory còn lại các bộ nhớ con để tự Oracle phân bổ theo AMM hoặc ASMM.
2.2.KẾT
NỐI TỚI ORACLE SERVER
2.2.1. Mô
hình kết nối
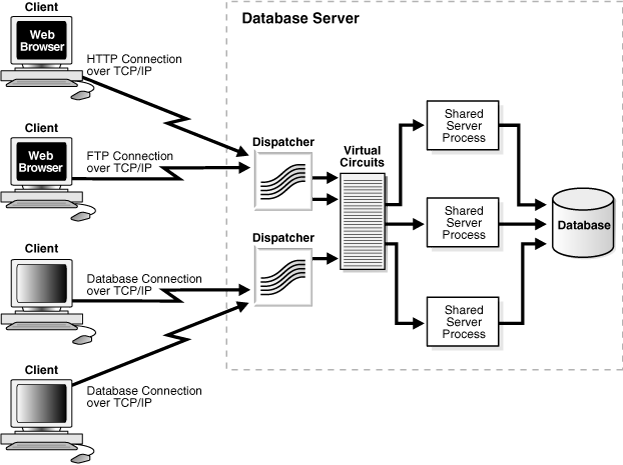
Các
Client có thể kết nối tới Oracle Server thông qua 03 cách sau:
§Kết nối
trực tiếp: kết nối mà Client nằm trên cùng một máy chủ Oracle server.
§Kết nối
hai lớp (two-tiered) client-server: Client nằm trên một máy tính khác và kết nối
trực tiếp tới máy chủ Oracle Server.
§Kết nối
ba lớp (three-tiered): Client nằm trên máy tính khác với máy chủ Oracle Server,
nó giao tiếp với một ứng dụng hay một máy chủ mạng (network server) và điều khiển
ứng dụng hay máy chủ này kết nối tới Oracle server.
Hình vẽ 9.Kết nối tới Oracle server
2.2.2. Một
số khái niệm cơ bản liên quan đến kết nối
Connection (liên kết)
Liên
kết là đường liên lạc giữa một user process và một Oracle server. Trong trường
hợp user sử dụng các tool hoặc các ứng dụng ngay trên cùng một máy với Oracle
server, đường liên lạc sẽ được tạo lập ngay trên máy đó. Trong trường hợp user
nằm trên một máy khác thì liên kết sẽ sử dụng đường mạng để kết nối tới Oracle
server.
Session (phiên)
Một
phiên tương ứng với một liên kết cụ thể của một user tới một Oracle server.
Phiên bắt đầu khi user kết nối tới Oracle Server đã được kiểm tra hợp lệ và kết
thúc khi user thực hiện log out khỏi Oracle Server hoặc user kết thúc một cách
bất thường. Một user cùng một lúc có thể có nhiều phiên làm việc để kết nối tới
Oracle Server thông qua các ứng dụng hay các tool khác nhau. Ví du: User có thể
đồng thời có các phiên làm việc giữa SQL*Plus, TOAD, SQL Navigator,... tới
Oracle Server.
Lưu
ý: Phiên chỉ tạo lập được khi Oracle Server đã sẵn sàng cho việc kết nối của
các client.
2.2.3. Kết
nối tới database
Các bước thực hiện kết nối
Để
kết nối tới database trước tiên, cần phải tạo liên kết tới Oracle Server. Liên
kết tới Oracle Server được tạo theo các bước sau:
§User sử
dụng công cụ SQL*Plus hay sử dụng các công cụ khác của Oracle như TOAD, SQL Navigator, SQL Developer để khởi tạo tiến trình. Trong mô hình Client-Server, các
công cụ hay ứng dụng này được chạy trên máy Client.
§User thực
hiện log in vào Oracle server với việc khai báo username, password và tên liên
kết tới database. Các ứng dụng tools sẽ tạo một tiến trình để kết nối tới
Oracle server qua các tham số này. Tiến trình này được gọi là tiến trình phục vụ.
Tiến trình phục vụ sẽ giao tiếp với Oracle server thay cho tiến trình của user
chạy trên máy Client.
Ví dụ thực hiện kết nối tới database
Để
hiểu rõ hơn về các bước thực hiện kết nối, ta hãy xem xét một ví dụ mô tả việc
kết nối tới Oracle database thực hiện bởi một user tại một máy tính khác có kết
nối tới máy tính mà Oracle server đang chạy trên đó. Việc kết nối được thực hiện
thông qua đường mạng bằng cách sử dụng dịch vụ Oracle Net8.
Tại máy chủ, cần đảm bảo Oracle server đang chạy
và sẵn sàng đón nhận các tín hiệu từ phía Client. Máy chủ này được gọi là host
hay database server.
Tại một máy trạm có chạy các ứng dụng (gọi là local
machine hay client workstation) sẽ thực hiện các user process để
kết nối tới database. Client application thực hiện thiết lập một kết nối tới
server thông qua Net driver.
Máy chủ server trên đó có các Net driver. Server
sẽ thực hiện việc nghe và dò tìm tất cả các yêu cầu gửi đến từ phía client
và sau đó sẽ tạo một server process tương ứng với user process.
Khi user thực hiện một câu lệnh SQL hay commit một
transaction. Ví dụ như user update dữ liệu trên một dòng trong một table.
Server process sẽ nhận về câu lệnh gửi tới từ
Client, kiểm tra và phân tích câu lệnh, việc này được thực hiện trong
shared pool. Tiếp theo đó, Server process sẽ kiểm tra quyền truy nhập dữ liệu
của user.
Server process trả về các giá trị dữ liệu yêu cầu
từ các dữ liệu có trong datafile hay trong system global area.
Server process thay đổi các dữ liệu có trong
data buffer cache. DBWn process ghi lại các blocks đã thay đổi ra ổ
đĩa. LGWR process sẽ ghi lại ngay lập tức các bản ghi thay
đổi vào online redo log file ngay khi transaction được commit.
Trong trường hợp transaction thực hiện thành
công, server process sẽ gửi thông báo hoàn tất qua đường mạng tới Client.
Ngược lại, sẽ có một error message gửi tới Client.
2.3. Áp dụng kiến trúc Cơ sở dữ liệu Oracle để hiểu hoạt động SELECT, INSERT, UPDATE, DELETE
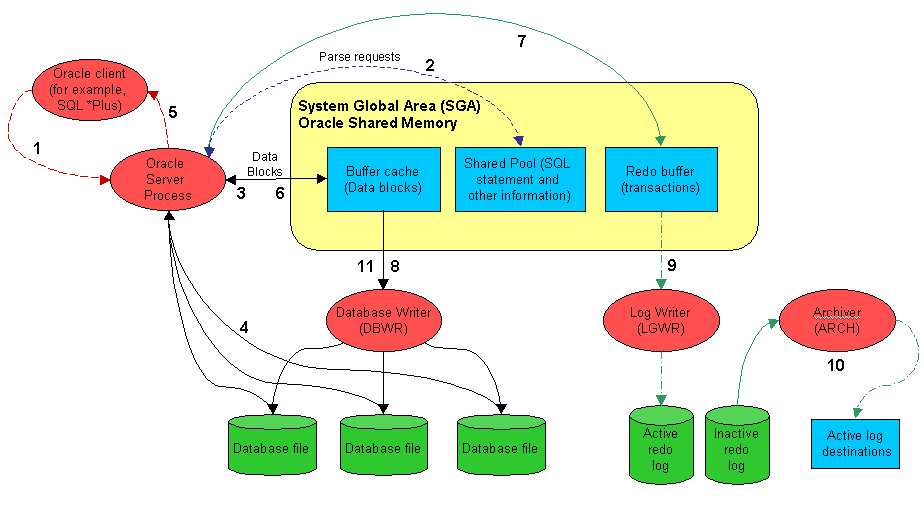
Sơ đồ sau minh họa một số thành phần cơ bản của máy chủ Oracle ở các lớp bộ nhớ, cơ sở dữ liệu và đĩa. Kiến trúc này đã được sử dụng để thiết kế Spotlight trên trang chủ Oracle.
Các con số cho biết thứ tự của luồng thông tin.
Các nhãn được đánh số trong sơ đồ kiến trúc Oracle tương ứng với các hoạt động sau:
Chương trình máy khách (ví dụ: SQL * PLUS, Oracle Power Objects hoặc một số công cụ khác) gửi một câu lệnh SELECT * from CUSTOMER where CUST_ID<1000 tới server process.
Server process tìm kiếm trong shared pool để tìm một câu lệnh SQL đã phân tích phù hợp. Nếu không tìm thấy, Server process phân tích cú pháp SQL và chèn câu lệnh SQL vào shared pool.
Server process tìm kiếm trong bộ đệm cache các block dữ liệu được yêu cầu. Nếu được tìm thấy, block dữ liệu phải được chuyển đến phần cuối được sử dụng gần đây nhất của danh sách Ít được sử dụng Gần đây nhất (Least Recently Used - LRU).
Nếu block không thể được tìm thấy trong bộ đệm cache, server process phải tìm nạp nó từ datafile trên đĩa. Điều này yêu cầu một I/O đĩa.
Server process trả về các row được truy xuất cho tiến trình máy khách. Điều này có thể liên quan đến mạng hoặc sự chậm trễ liên lạc.
Khi máy khách đưa ra câu lệnh UPDATE CUSTOMER set name='BINH_NEW' WHERE CUST_ID<1234, quá trình phân tích cú pháp SQL và truy xuất các row được cập nhật phải xảy ra. Sau đó, câu lệnh cập nhật sẽ thay đổi các block có liên quan trong bộ nhớ dùng chung (shared memory) và cập nhật các mục nhập trong bộ đệm rollback segment.
Câu lệnh cập nhật cũng tạo một mục nhập trong redo log ghi lại chi tiết giao dịch.
Background Process của database-writer sao chép các block đã sửa đổi từ data buffer cache vào các tệp cơ sở dữ liệu. Phiên Oracle thực hiện cập nhật không phải đợi điều này xảy ra.
Khi câu lệnh COMMIT được đưa ra, tiến trình log writer (LGWR) phải sao chép nội dung của redo log buffer vào redo log file. Câu lệnh COMMIT không trả lại quyền điều khiển các block đó cho phiên Oracle cho đến khi quá trình ghi này hoàn tất.
Nếu chạy ở chế độ ARCHIVELOG, trình lưu trữ sẽ sao chép toàn bộ các redo log đến archive. Redo log không đủ điều kiện để sử dụng lại cho đến khi nó đã được lưu trữ (archived).
Trong các khoảng thời gian đều đặn, hoặc khi xảy ra quá trình redo log switch, Oracle thực hiện checkpoint. Checkpoint yêu cầu tất cả các block đã sửa đổi (dirty block) trong bộ đệm đệm phải được ghi vào đĩa. Không thể sử dụng lại redo log file cho đến khi checkpoint hoàn thành.
Website không bao giờ chứa bất kỳ quảng cáo nào, mọi đóng góp để duy trì phát triển cho website (donation) xin vui lòng gửi về STK 90.2142.8888 - Ngân hàng Vietcombank Thăng Long - TRAN VAN BINH
=============================
Nếu bạn muốn tiết kiệm 3-5 NĂM trên con đường trở thành DBA chuyên nghiệp thì hãy đăng ký ngay KHOÁ HỌC ORACLE DATABASE A-Z ENTERPRISE, được Coaching trực tiếp từ tôi với toàn bộ kinh nghiệm, thủ tục, quy trình, bí kíp thực chiến mà bạn sẽ KHÔNG THỂ tìm kiếm trên Internet/Google giúp bạn dễ dàng quản trị mọi hệ thống Core tại Việt Nam và trên thế giới, đỗ OCP.
- CÁCH ĐĂNG KÝ: Gõ (.) hoặc để lại số điện thoại hoặc inbox https://m.me/tranvanbinh.vn hoặc Hotline/Zalo 090.29.12.888
👨 Địa chỉ: Tòa nhà Sun Square - 21 Lê Đức Thọ - Phường Mỹ Đình 1 - Quận Nam Từ Liêm - TP.Hà Nội
=============================
HỌC ORACLE DATABASE CƠ BẢN TỪ A-Z - BÀI 2: CÁC THÀNH PHẦN KIẾN TRÚC ORACLE DATABASE A-Z, oracle tutorial, học oracle database, Tự học Oracle, Tài liệu Oracle 12c tiếng Việt, Hướng dẫn sử dụng Oracle Database, Oracle SQL cơ bản, Oracle SQL là gì, Khóa học Oracle Hà Nội, Học chứng chỉ Oracle ở đầu, Khóa học Oracle online,sql tutorial, khóa học pl/sql tutorial, học dba, học dba ở việt nam, khóa học dba, khóa học dba sql, tài liệu học dba oracle, Khóa học Oracle online, học oracle sql, học oracle ở đâu tphcm, học oracle bắt đầu từ đâu, học oracle ở hà nội, oracle database tutorial, oracle database 12c, oracle database là gì, oracle database 11g, oracle download, oracle database 19c, oracle dba tutorial, oracle tunning, sql tunning , oracle 12c, oracle multitenant, Container Databases (CDB), Pluggable Databases (PDB), oracle cloud, oracle security, oracle fga, audit_trail,oracle RAC, ASM, oracle dataguard, oracle goldengate, mview, oracle exadata, oracle oca, oracle ocp, oracle ocm , oracle weblogic, postgresql tutorial, mysql tutorial, mariadb tutorial, ms sql server tutorial, nosql, mongodb tutorial, oci, cloud, middleware tutorial, hoc solaris tutorial, hoc linux tutorial, hoc aix tutorial, unix tutorial, securecrt, xshell, mobaxterm, putty