
Chúng tôi tin rằng SQL đã trở thành “eo hẹp” trong phân tích data
Kể từ khi máy tính chào đời, chúng ta đã chứng kiến sự phát triển về khối lượng data, đòi hỏi công nghệ lưu trữ data, xử lí và phân tích cũng phải được nâng tầm theo. Trong thập kỉ vừa qua, software developer xem SQL như là một di tích khi không thể theo kịp tốc độ phát triển của data volume, dẫn đến sự nổi lên của NoSQL: MapReduce và Bigtable, Cassandra, MongoDB, và nhiều nữa.
Thế nhưng SQL đã bắt đầu sống dậy. Tất cả các bên cung cấp dịch vụ cloud giờ còn có cả dịch vụ managed relational database như: Amazon RDS, Google Cloud SQL, Azure Database cho PostgreSQL. Theo Amazon, PostgreSQL- và MySQL-compatible database Aurora database của hãng là dịch vụ có tốc độ phát triển nhanh nhất trong lịch sử của AWS. SQL interfaces của Hadoop và Spark liên tục được cải thiện. Tháng vừa rồi thì Kafka launched SQL support.
Trong bài viết này chúng ta sẽ tìm hiểu nguyên nhân cho sự hồi sinh của SQL, cũng như ý nghĩa của nó đối với tương lai của data engineering và analysis.
Part 1: A New Hope – Một hi vọng mới
Để hiểu được vì sao SQL trở lại ta phải quay về cội nguồn xuất phát của nó.

Câu chuyện của chúng ta bắt đầu với ngiên cứu của IBM trong những năm đầu của thập niên 70s. Khi đó, các ngôn ngữ query vẫn còn dựa rất nhiều vào thuật toán phức tạp. Donald Chamberlin và Raymond Boyce, hai chàng trai còn “non” trong thế giới lập trình, đã vô cùng ấn tượng với relational data model nhưng họ nhận ra các ngôn ngữ query sẽ chỉ làm “nghẽn lỗ chai”. Do đó cả hai quyết tâm tạo ra một ngôn ngữ query mới, dễ hiểu cho ngay cả user không giỏi toán học và computer programming.

Đây là thời điểm trước cả internet, máy tính cá nhân, khi mà C chỉ vừa mới được giới thiệu với toàn thế giới, đã có 2 nhà khoa học máy tính trẻ nhận ra rằng sự thành công của ngành công nghệ đa phần đến từ việc phát triển một nhóm người dùng thay vì bỏ công đào tạo các chuyên gia lập trình. Họ muốn một ngôn ngữ query dễ đọc như tiếng anh.
Kết quả là thế giới biết tới SQL vào năm 1974. và trong vài thập kỉ tiếp theo, SQL sẽ trở nên vô cùng nổi tiếng. Các database như System R, Ingres, DB2, Oracle, SQL Server, PostgreSQL, MySQL cũng nhanh chóng đô hộ cả ngành công nghệ software. SQL được xem như cầu nối tới database cũng như là lingua franca giúp tăng sự đa dạng cho ecosystem.
Trong một khoảng thời gian, SQL gần như là một ông hoàn cho đến khi Internet xuất hiện.
Part 2: NoSQL Strikes Back – NoSQL tấn công
Trong khi Chamberlin và Boyce đang phát triển SQL, cả hai đều không hay biết việc một nhóm engineer tại California đang thực hiện một project mà sau này đe dọa tới sự tồn tại của SQL. Nó có tên gọi là ARPANET, chào đời vào ngày 29 tháng 10 năm 1969.

Thế nhưng SQL vẫn sống khỏe cho đến khi một engineer khác xuất hiện và sáng tạo ra World Wide Web vào 1989.

Như cỏ dại sau mưa, Internet và Web phát triển mạnh mẽ, ảnh hưởng đến thế giới của chúng ta tại nhiều phương diện khác nhau, nhưng với cộng đồng data thì một vấn đề mới đã xuất hiện: các nguồn mới generate data với volume và vận tốc ngày càng cao.
Và khi Internet ngày càng to lớn thì cộng đồng cũng phát hiện rằng relational databases tại thời điểm đó không đủ khả năng để load khối lượng data như vậy dẫn đến hiện trạng overload của rất nhiều database khác nhau.
Ngay lúc đó 2 ông lớn Internet đã đột phá khi phát triển ra các distributed non-relational systems mới để cứu vãn tình hình: MapReduce (2004) và Bigtable (2006) bởi Google, Dynamo (2007) bởi Amazon. Chúng còn dẫn tới sự ra đời của các non-relational databases, bao gồm Hadoop, Cassandra và MongoDB. Do các systems này được tạo ra từ con số không, chúng cũng xung đột với SQL, dẫn tới sự bùng nổ của NoSQL.
Không có gì ngạc nhiên khi cộng đồng software developer chào đón NoSQL vô cùng nồng nhiệt. Sao mà không phấn khích khi NoSQL vừa mới vừa đẹp, chứa đựng sức mạnh và qui mô lớn, cứ như rằng nó chính là con đường thành công dành cho engineer. Thế rồi vấn đề mới lại xuất hiện.

Developer nhanh chóng nhận ra việc thiếu vắng SQL hóa ra lại khiến mọi thứ khá giới hạn. Do mỗi NoSQL database đều có một ngôn ngữ query riêng cũng như qui luật riêng, kèm theo đó hệ ecosystem nghèo nàn khiến cho không chỉ việc học chúng đã khó mà kết nối các database tới app cũng trở nên phức tạp. Đó là chưa kể các công ty còn phải tự phát triển tool phù hợp cho riêng mình.
Những ngôn ngữ NoSQL này do còn mới nên chúng cũng chưa thật sự trưởng thành, trong khi với SQL thì đã có nhiều năm phát triển relational databases giúp các tính năng của nó đã được cải thiện. Do đó, sự non nớt của NoSQL khiến tăng mức độ phức tạp khi làm app. Sự thiếu vắng của JOINs cũng gây ra các vấn đề đối với data.
Một vài NoSQL databases đã thử phát triển những ngôn ngữ Query tương tự như “SQL” (Cassandra’s CQL) nhưng nó lại khiến mọi thứ tệ hơn với việc các engineers bị nhầm lẫn khi sử dụng nó.

Sau một thời gian khổ cực, ngày càng có nhiều developer chán nản với NoSQL.
Part 3: Return of the SQL – Sự trở lại của SQL

Sau khi bị cám dỗ lạc vào trong đêm tối, công đồng software bắt đầu nhìn thấy ánh sáng và trở về với SQL.
Tiếp theo đó sự trỗi dậy của NewSQL mới: Một databases có khả năng mở rộng và hoàn toàn dành cho SQL. H-Store (2008), thành quả của các nhà nghiên cứu của MIT và Brown, là một trong những OLTP databases đầu tiên. Google tiếp tục dẫn đầu cuộc đua với SQL-interfaced database trong Spanner, theo sau đó là CockroachDB (2014).
Cùng lúc đó, cộng đồng PostgreSQL bắt đầu sống lại, thêm vào những tính năng vô cùng quan trọng như JSON datatype (2012), cũng như trong PostgreSQL 10: native support tốt hơn, text search support cho JSON, và nhiều hơn nữa. Các công ty khác như CitusDB (2016) và yours truly (TimescaleDB) cũng đã tiềm ra cách máy để mở rộng PostgreSQL để tập trung vào data workloads.

Hơn thế TimescaleDB cũng như tấm gương phản chiếu lịch sự của chính SQL. Khi trong nhưng phiên bản đầu tiên, TimescaleDB cũng sử dụng ngôn ngữ query từa tựa SQL gọi là “ioQL.”. Ban đầu, chúng tôi cũng bị cám dỗ và nghĩ việc tạo ra một ngôn ngữ riêng đầy mạnh mẽ thật sự rất có ích. Nhưng khi bắt đầu đi sâu thì nó có rất nhiều vấn đề nảy sinh từ thuật toán cho đến việc hướng dẫn user.
Và sau một thời gian, chúng tôi nhận ra rằng việc tạo ra một ngôn ngữ mới hoàn toàn phí công và ta nên tìm cách để thật sự sử dụng SQL. Ngay lập tức một thế giới mới như mở ra trước mắt chúng tôi. Hiện nay, dù database chỉ mới được 5 tháng nhưng các user đã có thể làm nhiều việc khác nhau như visualization tools (Tableau), kết nối tới ORMs, etc…
Hãy dõi theo Google

Google rõ ràng là người dẫn đầu trong cuộc thi công nghệ trong hơn một thập kỉ vừa qua. Do đó, khi nói đến việc tìm hiểu về công nghệ mới thì không có gì hơn việc theo dõi nguồn tin từ ông lớn công nghệ này.
Hãy thử xem Spanner của Google (Spanner trở thành một SQL System, 2017), và bạn sẽ nhận thấy rất nhiều chi tiết thú vị.
Ví dụ như khi Google bắt đầu tạo nó trên Bigtable, họ phát hiện ra việc thiếu SQL gây ra nhiều vấn đề nhức đầu:
“Trong khi những hệ thống này cung cấp một vài lợi ích của một database system, chúng lại thiếu nhiều database feature mà các developer vẫn thường hay dựa vào. Do không có một ngôn ngữ query mạnh mẽ nên developer phải bỏ ra rất nhiều thời gian cũng như phải thực hiện nhiều bước phức tạp. Do đó mà chúng tôi đã quyết định biến Spanner thành full featured SQL system, với query execution được tích hợp chặt trẽ với các tính năng khác của Spanner”
Sau đó, hãng cũng nói rõ thêm vì sao lại lựa chọn chuyển đổi từ NoSQL qua SQL:
“API của Spanner cung cấp NoSQL methods cho point lookup và range scan. Trong khi NoSQL methods cung cấp một cách thức đơn giản để launch Spanner, và tỏ ra rất hữu ích trong những trường hợp đơn giản, SQL vẫn đưa ra những giá trị vô cùng to lớn khi có khả năng xử lí các data access pattern phức tạp và push thuật toán tới data.”
Không chỉ dừng lại với spanner mà SQL còn được Google áp dụng vào nhiều system của hãng:
“SQL engine của Spanner cùng sử dụng chung một SQL dialect, được gọi là “Standard SQL”, cùng với các hệ thống nội bộ khác tại Google như F1 và Dremel cũng như hệ thống bên ngoài như BigQuery…
Với user trong Google, nó giúp giảm độ phức tạp khi làm việc giữa nhiều hệ thống khác nhau. Một developer hay nhà phân tích data khi viết SQL cho Spanner database vẫn có thể chuyển qua Dremel mà không phải lo về sự khác biệt trong ngôn ngữ”.
Cách tiếp cận này đã thành công vượt ngoài tưởng tượng với spanner đóng vai trò chủ chốt trong hệ thống của Google, bao gồm AdWords và Google Play, “Các khách hàng đám mây điển tử cũng rất quan tâm và thích thú với SQL.”
Điều này có ý nghĩa gì cho tương lai?
Trong computer networking, có một thuật ngữ gọi là “eo hẹp”
Nó ám chỉ việc trong hệ thống network với nhiều lớp hardware ở dưới và software ở trên. Mỗi phần cứng và phần mềm luôn khác biệt nhau nên ta phải bảo đảm bất kể là phần cứng gì thì phần mềm vẫn có thể kết nối với network. Ngược lại, bất kể phần mềm nào thì phần cứng vẫn xử lí được network requests.
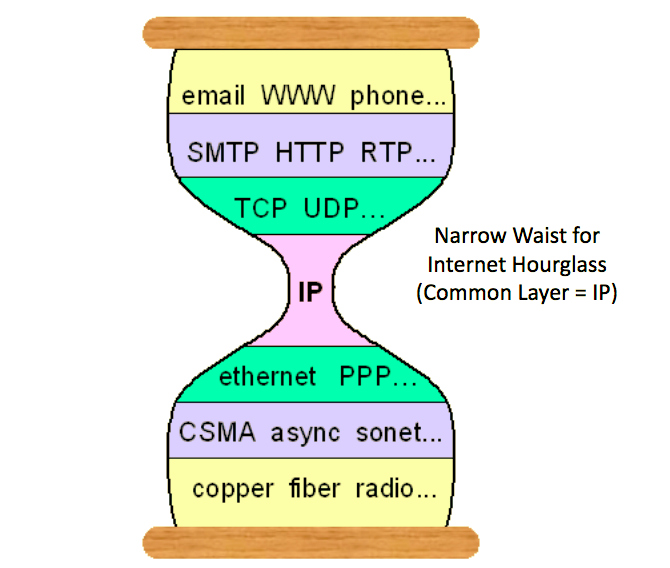
Trong networking, vai trò của “eo hẹp” được thực hiện bởi Internet Protocol (IP) như một interface thông thường giữ networking protocols cấp thấp (dành cho local-area network) và application and transport protocols cấp cao. có thể nói IP đóng vai trò như người thông dịch cho phép kết nối và giao tiếp giữa các thiết bị.
Chúng tôi tin rằng SQL đã trở thành “eo hẹp” trong phân tích data
Chúng ta đang sống trong thời đại mà data chính là nguồn tư liệu quí giá nhất. Kết quả là sự bùng nổ về databases (Olap, time-series, tài liệu, graph, etc), tools xử lí data (Hadoop, Spark, Flink), data buses (Kafka, RabbitMQ), etc. Đồng thời chúng ta có ngày càng có nhiều app dựa trên cấu trúc data này.
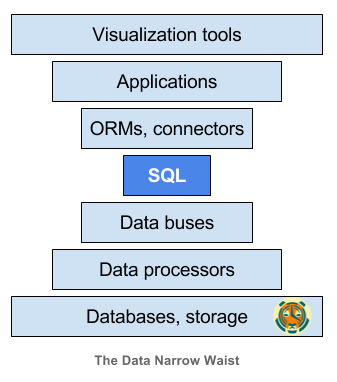
Tương tự như network chúng ta cũng có một stack phức tạp với cơ sở ở dưới và app ở trên. Do đó mà ta thường phải viết khá nhiều code để gắn chúng lại với nhau. Nhưng những code thì rất dễ “vỡ” nên đòi hỏi phải được chăm sóc và bảo trì.
Điều chúng ta cần là một interface chung để các phần trong stack trên có thể giao tiếp với nhau. Và sẽ là rất lí tưởng khi ta có một interface chuẩn cho phép việc thay ra/vào các thành phần mà không phải lo về việc crash hoặc lỗi.
Đây chính là lúc SQL tỏa sáng bởi cũng như IP, SQL là một interface chuẩn chung.
Không những thế mà SQL còn rất dễ đọc
SQL đã quay trở lại
SQL đã trở lại. Không phải chỉ vì NoSQL quá ư là tởm lợm. Cũng không phải chỉ do việc phải học ngôn ngữ mới quá phiền phức. Cũng không phải chỉ là do SQL đạt chuẩn.
Mà còn là vì thế giới này tràn ngập Data. chúng ở khắp mọi nơi và liên kết lẫn trói buộc chúng ta. Ban đầu ta có thể dựa vào các giác quan và não để giải quyết. Sau đó, khi mà máy móc trở nên thông minh hơn thì chúng thay ta làm những công việc này. Việc có thể xử lý càng nhiều data càng giúp chúng ta có khả năng nhận thức cao hơn, rõ ràng hơn và đồng thời nó khiến cho hệ thống lưu trữ data phát triển hơn bao giờ hết.

Chỉ có 2 lựa chọn cho chúng ta: phải sống trong một thế giới với đống data lộn xộn, code dễ hư với hàng triệu interface khác nhau, hoặc là chọn SQL và thống nhất mọi thứ.
Hy vọng hữu ích cho bạn.
* KHOÁ HỌC ORACLE DATABASE A-Z ENTERPRISE trực tiếp từ tôi giúp bạn bước đầu trở thành những chuyên gia DBA, đủ kinh nghiệm đi thi chứng chỉ OA/OCP, đặc biệt là rất nhiều kinh nghiệm, bí kíp thực chiến trên các hệ thống Core tại VN chỉ sau 1 khoá học.
* CÁCH ĐĂNG KÝ: Gõ (.) hoặc để lại số điện thoại hoặc inbox https://m.me/tranvanbinh.vn hoặc Hotline/Zalo 090.29.12.888
* Chi tiết tham khảo:
https://bit.ly/oaz_w
=============================
KẾT NỐI VỚI CHUYÊN GIA TRẦN VĂN BÌNH:
📧 Mail: binhoracle@gmail.com
☎️ Mobile/Zalo: 0902912888
👨 Facebook: https://www.facebook.com/BinhOracleMaster
👨 Inbox Messenger: https://m.me/101036604657441 (profile)
👨 Fanpage: https://www.facebook.com/tranvanbinh.vn
👨 Inbox Fanpage: https://m.me/tranvanbinh.vn
👨👩 Group FB: https://www.facebook.com/groups/DBAVietNam
👨 Website: https://www.tranvanbinh.vn
👨 Blogger: https://tranvanbinhmaster.blogspot.com
🎬 Youtube: https://www.youtube.com/@binhguru
👨 Tiktok: https://www.tiktok.com/@binhguru
👨 Linkin: https://www.linkedin.com/in/binhoracle
👨 Twitter: https://twitter.com/binhguru
👨 Podcast: https://www.podbean.com/pu/pbblog-eskre-5f82d6
👨 Địa chỉ: Tòa nhà Sun Square - 21 Lê Đức Thọ - Phường Mỹ Đình 1 - Quận Nam Từ Liêm - TP.Hà Nội
=============================
oracle tutorial, học oracle database, Tự học Oracle, Tài liệu Oracle 12c tiếng Việt, Hướng dẫn sử dụng Oracle Database, Oracle SQL cơ bản, Oracle SQL là gì, Khóa học Oracle Hà Nội, Học chứng chỉ Oracle ở đầu, Khóa học Oracle online,sql tutorial, khóa học pl/sql tutorial, học dba, học dba ở việt nam, khóa học dba, khóa học dba sql, tài liệu học dba oracle, Khóa học Oracle online, học oracle sql, học oracle ở đâu tphcm, học oracle bắt đầu từ đâu, học oracle ở hà nội, oracle database tutorial, oracle database 12c, oracle database là gì, oracle database 11g, oracle download, oracle database 19c, oracle dba tutorial, oracle tunning, sql tunning , oracle 12c, oracle multitenant, Container Databases (CDB), Pluggable Databases (PDB), oracle cloud, oracle security, oracle fga, audit_trail,oracle RAC, ASM, oracle dataguard, oracle goldengate, mview, oracle exadata, oracle oca, oracle ocp, oracle ocm , oracle weblogic, postgresql tutorial, mysql tutorial, mariadb tutorial, sql server tutorial, nosql, mongodb tutorial, oci, cloud, middleware tutorial, hoc solaris tutorial, hoc linux tutorial, hoc aix tutorial, unix tutorial, securecrt, xshell, mobaxterm, putty



