
Được giới thiệu lần đầu vào năm 1989, bởi nhóm nghiên cứu ở đại học California. PostgreSQL được gọi là cơ sở dữ liệu mã nguồn mở tiên tiến nhất thế giới, cho đến thời điểm hiện tại, theo db_engines, nó là cơ sở dữ liệu phổ biến thứ 4 trên thế giới, và được nhiều ông lớn sử dụng như Uber, Netflix, Instagram hay Spotify. Ở bài viết này ta sẽ tìm hiểu kiến trúc nền của PostgreSQL.
Danh mục
- Bộ nhớ
- Tiến trình
- Cơ sở dữ liệu
- Cấu trúc thư mục
- Vacuum
Kiến trúc PostgreSQL
Ta có kiến trúc của PostgreSQL đơn giản như sau. Nó bao gồm một bộ nhớ chung, một vài tiến trình nền và các file dữ liệu.
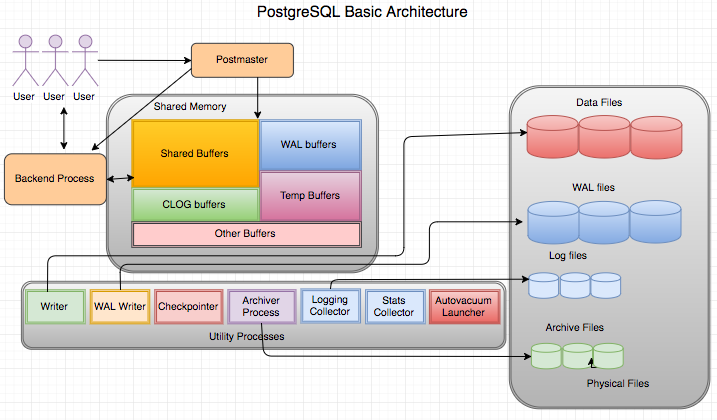
Bộ nhớ chung
Bộ nhớ chung(Shared Memory) là bộ nhớ dành riêng cho lưu trữ cơ sở dữ liệu và nhật ký giao dịch. Các thành phần quan trọng của bộ nhớ chung có thể kể đến là Shared Buffer, WAL Buffer, CLOG Buffer, Temp Buffer, Work Memory và Vacuum Buffer.
Shared Buffer
Thao tác đọc và ghi trong bộ nhớ luôn nhanh hơn bất kỳ thao tác nào khác. Thế nên các cơ sở dữ liệu luôn cần bộ nhớ để truy cập nhanh dữ liệu, mỗi khi có truy cập READ và WRITE xuất hiện. Trong PostgreSQL đấy chính là Shared Buffer (được điều khiển bởi tham số shared_buffers). Dung lượng RAM được cấp phát cho Shared Buffer sẽ là cố định trong suốt thời gian chạy PostgreSQL. Shared Buffer có thể được truy cập bởi tất cả tiến trình server và người dùng kết nối đến cơ sở dữ liệu.
Dữ liệu được ghi hay chỉnh sửa trong Shared Buffer được gọi là dirty data, và các đơn vị thao tác trong csdl block (hay page) thay đổi được gọi là dirty block hay dirty page. Dirty data sẽ được ghi vào file vật lý liên tục trên ở đĩa, các file này được gọi là file dữ liệu (data file).
Mục đích của Shared Buffer là để giảm thiểu các tác vụ I/O lên đĩa (DISK IO). Để đạt được mục đích đó, nó phải đáp ứng được những yêu cầu sau:
- Phải truy cập bộ nhớ đệm lớn(hàng chục, trăm gigabites) nhanh chóng.
- Tối thiểu hoá xung đột khi nhiều người dùng truy cập cùng lúc.
- Các blocks được sử dụng thường xuyên phải ở trong bộ đệm càng lâu càng tốt.
WAL Buffer
WAL Buffer còn gọi là transaction log buffers, là bộ nhớ đệm để lưu trữ dữ liệu WAL. Dữ liệu WAL là thông tin về những thay đổi đối với dữ liệu thực tế và dùng để tạo lại dữ liệu trong quá trình sao lưu và phục hồi cơ sở dữ liệu. Dữ liệu WAL được ghi trong file vật lý ở các vị trí liên tục gọi là WAL segments hoặc checkpoint segments.
WAL Buffer được điều khiển bởi tham số wal_buffers, nó được cấp phát bởi RAM của hệ điều hành. Mặc dù nó cũng có thể được truy cập bởi tất cả tiến trình server và người dùng, nhưng nó không phải là một phần của Shared Bufer. WAL Buffer nằm ngoài Shared Buffer và rất nhỏ nếu so sánh với Shared Buffer. Dữ liệu WAL lần đầu tiên sửa đổi sẽ được ghi vào WAL Buffer trước khi được ghi vào WAL Segments trên ổ đĩa. Theo thiết lập mặc định, nó sẽ được phân bổ với kích thước bằng 1/16 Shared Buffer.
CLOG Buffer
CLOG là viết tắt của commit log, và CLOG Buffer là bộ đệm dành riêng cho lưu trữ các trang commit log được cấp phát bởi RAM của hệ điều hành. Các trang commit log chứa nhật ký về giao dịch và các thông tin khác từ dữ liệu WAL. Các commit log chứa trạng thái commit của tất cả giao dịch và cho biết một giao dịch đã hoàn thành hay chưa.
Không có tham số cụ thể để kiểm soát vùng nhớ này. Sẽ có công cụ cơ sở dữ liệu tự động quản lý với số lượng rất nhỏ. Đây là thành phần nhớ dùng chung, có thể được truy cập bởi tất cả tiến trình server và người dùng của csdl PostgreSQL.
Memory for Lock
Thành phần nhớ này là để lưu trữ tất cả các khóa(lock) nặng được sử dụng bởi PostgreSQL. Các khoá này được chia sẻ trên tất cả tiến trình server hay user kết nối đến csdl. Một thiết lập (không mặc định) giữa hai tham số là max_locks_per_transaction và max_pred_locks_per_transaction sẽ ảnh hưởng theo một cách nào đó đến kích thước của bộ nhớ này.
Vacuum Buffer
Đây là lượng bộ nhớ tối đa được sử dụng cho mỗi tiến trình autovacuum worker, được điều khiển bởi tham số autovacuum_work_mem. Bộ nhớ được cấp phát bởi RAM của hệ điều hành. Tất cả thiết lập tham số chỉ có hiệu quả khi tiến trình auto vacuum được bật, nếu không các thiết lập này sẽ không ảnh hưởng đến VACUUM đang chạy ở ngữ cảnh khác. Thành phần nhớ này không được chia sẻ bởi bất kỳ tiến trình máy chủ hay người dùng nào.
Work Memory
Đây là bộ nhớ dành riêng cho một thao tác sắp xếp hoặc bảng băm cho một truy vấn nào đó, được điều khiển bởi tham số work_mem. Thao tác sắp xếp có thể là ORDER BY, DISTINCT hay MERGE JOIN. Thao tác trên bảng băm có thể là hash-join hoặc truy vấn IN.
Các câu truy vấn phức tạp hơn như nhiều thao tác sắp xếp hoặc nhiều bảng băm có thể được cấp phát bởi tham số work_mem. Vì lý do đó không nên khai báo work_mem với giá trị quá lớn, vì nó có thể dẫn đến việc sử dụng vùng nhớ của hệ điều hành chỉ cho một câu truy vấn lớn, khiến hệ điều hành thiếu RAM cho các tiến trình cần thiết khác.
Maintenance Work Memory
Đây là lượng nhớ tối đa mà RAM sử dụng cho các hoạt động bảo trì(maintenance). Các hoạt động bảo trì có thể là VACUUM, CREATE INDEX hay FOREIGN KEY, và được kiểm soát bởi tham số maintenance_work_mem.
Một phiên cơ sở dữ liệu chỉ có thể thực hiện bất kỳ hoạt động bảo trì nào đã đề cập ở trên tại một thời điểm và PostgreSQL thường không thực hiện đồng thời nhiều hoạt động bảo trì như vậy. Do đó tham số này có thể thiết lập lớn hơn nhiều so với tham số work_mem.
Lưu ý: Không thiết lập giá trị cho tham số này quá cao, giá trị này sẽ phân bổ nhiều phần cấp phát bộ nhớ như được xác định bởi tham số autovacuum_max_workers trong trường hợp không định cấu hình tham số autovacuum_work_mem.
Temp Buffer
Các cơ sở dữ liệu cần một hay nhiều bảng mẫu, và các block(page) của bảng mẫu này cần nơi để lưu trữ. Temp Buffer sinh ra nhằm mục đích này, bằng cách sử dụng một phần RAM, được xác định bởi tham số temp_buffer.
Temp Buffer chỉ được sử dụng để truy cập bảng tạm thời trong phiên người dùng. Không có liên hệ gì giữa temp buffer với các file mẫu được tạo trong thư mục pgsql_tmp để thực hiện sắp xếp lớn hay bảng băm.
Loại tiến trình PostgreSQL
PostgreSQL có bốn loại tiến trình là:
- Postmaster (Daemon) Process
- Background Process
- Backend Process
- Client Process
Postmaster Process
Postmaster Process là tiến trình khởi tạo đầu tiên sau khi PostgreSQL khởi động. Tiến trình này đảm nhiệm việc khởi động hoặc dừng các tiến trình khác nếu cần hoặc có yêu cầu. Sau khi khởi động postmaster process sẽ khởi động các background process.
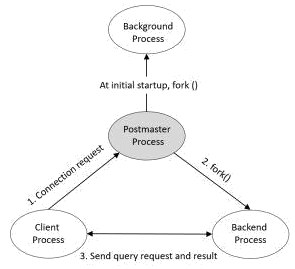
Nếu bạn kiểm tra mối quan hệ giữa các tiến trình bằng pstree, bạn sẽ thấy Postmaster Process là tiến trình cha của tất cả các tiến trình(để rõ ràng, tôi đã thêm tên và đối số theo sau id của tiến trình).

Background Process
Ta có danh sách các Background Process thường trực như sau:
logger
postgres 17400 17397 0 Apr11 ? 00:00:18 postgres: logger process
Tiến trình này đảm nhiệm việc ghi log của PostgreSQL.
checkpointer
postgres 17400 17397 0 Apr11 ? 00:00:18 postgres: checkpointer process
Tiến trình này chủ yếu giữ vai trò thực hiện checkpoint (đồng bộ dữ liệu từ bộ nhớ đệm xuống vùng lưu trữ) khi cần thiết.
writer
postgres 17401 17397 0 Apr11 ? 00:01:24 postgres: writer process
Tiến trình này kết hợp với checkpointer để đảm bảo việc ghi dữ liệu từ bộ đệm xuống vùng lưu trữ. Thông thường khi checkpoint không hoạt động, tiến trình này sẽ ghi từng chút một dữ liệu xuống vùng lưu trữ.
wal writer
postgres 17402 17397 0 Apr11 ? 00:01:31 postgres: wal writer process
Đảm nhiệm việc đồng bộ WAL từ bộ nhớ đệm xuống vùng lưu trữ. Thông thường WAL sẽ được ghi từ bộ đệm xuống vùng lưu trữ khi transaction được commit. Nếu dữ liệu đệm của WAL trên bộ nhớ đệm vượt quá tham số wal_buffers, dữ liệu WAL trên vùng nhớ đệm sẽ tự động ghi xuống vùng lưu trữ dữ liệu thông qua tiến trình này.
autovacuum launcher
postgres 17403 17397 0 Apr11 ? 00:06:13 postgres: autovacuum launcher process
Tiến trình này hoạt động khi tham số autovacuum = on. Nó thực hiện chức năng tự động lấy vùng dữ liệu dư thừa sau khi DELETE hoặc UPDATE dữ liệu. Tiến trình này khởi động các VACUUM worker processes sau mỗi autovacuum_naptime. Các VACUUM worker processes sẽ thực hiện việc VACUUM dữ liệu trên các database.
stats collector
postgres 17404 17397 0 Apr11 ? 00:11:30 postgres: stats collector process
Tiến trình này thực hiện vai trò lưu trữ các thông tin thống kê hoạt động của PostgreSQL và cập nhật vào các system catalog (thông tin nội bộ của PostgreSQL hiện diện bởi các bảng pg_stat_all_tables hoặc pg_stat_activity).
Backend Process
Số lượng tối đa backend process được thiết lập bởi tham số max_connections có giá trị mặc định là 100. Backend process thực hiện yêu cầu truy vấn của user process, sau đó truyền kết quả. Một số cấu trúc bộ nhớ được yêu cầu để thực thi truy vấn, được gọi là bộ nhớ cục bộ (local memory). Các tham số chính liên quan đến bộ nhớ cục bộ là:
work_memđược sử dụng cho điều chỉnh Work Memory. Thiết lập mặc định là 4 MB.maintenance_work_memđược sử dụng cho điều chỉnh Maintenance Work Memory. Thiết lập mặc định là 64 MB.temp_buffersđược sử dụng cho điều chỉnh Temp Buffer. Thiết lập mặc định là 8 MB.
Client Process
Client Process đề cập đến background process được chỉ định cho mội kết nối với người dùng. Thông thường, postmaster process sẽ phân ra một tiến trình con dành riêng phục vụ cho kết nối người dùng.
Cấu trúc database
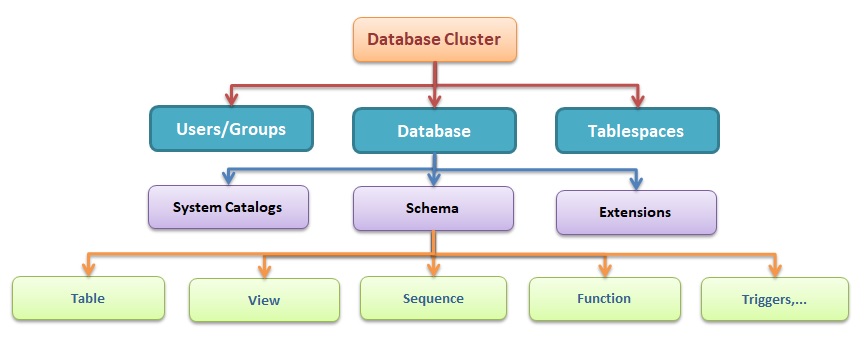
Dưới đây là các khái niệm quan trọng cần biết khi tìm hiểu cấu trúc cơ sở dữ liệu của PostgreSQL.
Database cluster
Là đơn vị lưu trữ lớn nhất của một PostgreSQL database server. Database cluster được tạo ra bởi câu lệnh initdb(), bao gồm các files config (postgresql.conf, pg_hba.conf, ...), và tất cả các đối tượng lưu trữ đều nằm trong database cluster.
Databases
Là đơn vị lớn sau Database cluster. Để thực hiện được câu truy vấn, bạn phải truy cập vào một database nào đó. Khi initdb() thực thi, mặc định PostgreSQL sẽ tạo ra 3 csdl là template0, template1 và postgres.
template0
Là cơ sở dữ liệu mẫu. Không thể truy nhập và chỉnh sửa các đối tượng trong đó. Người dùng có thể tạo database mới dựa trên template0 này bằng cách chỉ định TEMPLATE trong câu lệnh CREATE DATABASE
template1
Là cơ sở dữ liệu mẫu. Người dùng có thể truy nhập và chỉnh sửa các đối tượng trong đó. Khi thực hiện câu lệnh "CREATE DATABASE", PostgreSQL sẽ copy template1 này để tạo database mới.
postgres
Cơ sở dữ liệu mặc định của PostgreSQL khi tạo database cluster.
Tablespace
Là đơn vị lưu trữ dữ liệu về phương diện vật lý bên dưới database. Thông thường dữ liệu vật lý được lưu trữ tại thư mục dữ liệu (nơi ta chỉ định lúc ta tạo database cluster). Nhưng có một phương pháp lưu trữ dữ liệu ngoài phân vùng này, nhờ sử dụng chức năng TABLESPACE. Khi tạo một TABLESPACE tức là ta đã tạo ra một vùng lưu trữ dữ liệu mới độc lập với dữ liệu bên dưới thư mục dữ liệu. Điều này giảm thiểu được disk I/O cho phân vùng thư mục dữ liệu (nếu trong các hệ thống cấu hình RAID, hay hệ thống có 1 đĩa cứng thì không có hiệu quả).
Schema
Là đơn vị lưu trữ bên dưới database, quản lý dữ liệu dưới dạng logic. Mặc định trong mỗi database có một schema cho người sử dụng, đó là schema public. Ta có thể tạo schema bằng câu lệnh CREATE SCHEMA. Đặc điểm của 1 schema như sau:
- Có thể sử dụng tên trùng với schema ở database khác nhưng không trùng tên trên cùng database.
- Ngoài TABLESPACE và user ra, schema có thể chứa hầu hết các đối tượng còn lại (như table, index, sequence, constraint...) để truy cập schema ta có thể thêm tên schema vào phía trước đối tượng muốn truy cập hoặc sử dụng tham số
search_pathđể thay đổi schema truy cập hiện tại. - Schema có thể sử dụng với các mục đích như tăng cường bảo mật, quản lý dữ liệu dễ dàng hơn.
Bảng(table)
Bảng là đối tượng lưu trữ dữ liệu từ người dùng. Một bảng bao gồm 0 hoặc nhiều cột (column) tương ứng với từng kiểu dữ liệu khác nhau của PostgreSQL. Tổng quan có 3 kiểu tables mà PostgreSQL hỗ trợ, đó là:
- unlogged table: là kiểu table mà các thao tác đối với bảng dữ liệu này không được lưu trữ vào WAL. Tức là không có khả năng phục hồi nếu bị corrupt.
- temporary table: là kiểu table chỉ được tạo trong phiên làm việc đó. Khi connection bị ngắt, nó sẽ tự động mất đi.
- table thông thường: Khác với 2 kiểu table trên, là loại table thông thường để lưu trữ dữ liệu. Có khả năng phục hồi khi bị corrupt và tồn tại vĩnh viễn nếu không có thao tác xóa bỏ nào.
Cấu trúc thư mục
PostgreSQL có thể được cài đặt trên cả 3 môi trường: Linux, Unix và Windows.
Trên Linux và Unix, PostgreSQL được cài tại thư mục /usr/local/pgsql hoặc /var/lib/pgsql, còn trên môi trường Windows, là thư mục C:\Program Files\PostgreSQL\<version number>. Các file cấu hình và database được tổ chức ngay trong thư mục data, thể hiện qua biến môi trường $PGDATA.
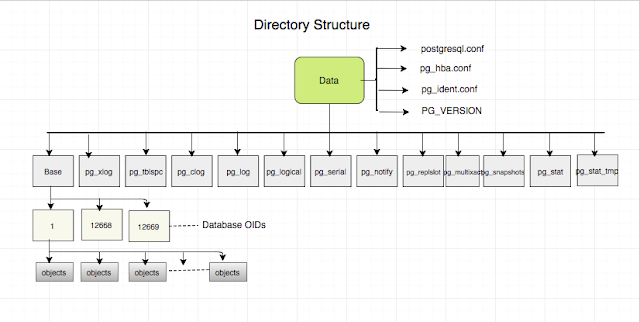
Ta có bảng ý nghĩa các file (v.13):
| Item | Nội dung |
|---|---|
| PG_VERSION | File chứa phiên bản hiện tại của PostgreSQL. |
| base | Thư mục con chứa cơ sở dữ liệu, trong thư mục này chứa các thư mục con nữa cho mỗi database. |
| current_logfiles | File ghi các file log được ghi bởi logging collector. |
| global | Thư mục con chứa các bảng nội bộ, chẳng hạn như pg_database. |
| pg_commit_ts | Thư mục con chứa thông tin về trạng thái commit của dữ liệu timestamp. |
| pg_dynshmem | Thư mục con chứa các file sử dụng dynamic shared memory. |
| pg_logical | Thư mục con chứa trạng thái dữ liệu sử dụng trong chức năng logical decoding. |
| pg_multixact | Thư mục con chứa dữ liệu trạng thái multitransaction (sử dụng cho locks mức độ dòng dữ liệu). |
| pg_notify | Thư mục con chứa dữ liệu về chức năng LISTEN/NOTIFY. |
| pg_replslot | Thư mục con chứa dữ liệu về replication slot. |
| pg_serial | Thư mục con chứa thông tin về các transaction commited ở mức độ phân li serializable. |
| pg_snapshots | Thư mục con chứa thông tin về các snapshots đã xuất. |
| pg_stat | Thư mục con chứa các files thông tin thống kê về PostgreSQL đang được sử dụng hiện tại. |
| pg_stat_tmp | Thư mục con chứa các files thông tin thống kê về PostgreSQL tạm thời. |
| pg_subtrans | Thư mục con chứa dữ liệu về các subtransaction. |
| pg_tblspc | Thư mục con chứa thông tin symbolic links tới các tablespaces. |
| pg_twophase | Thư mục con chứa các tập tin trạng thái cho các prepared transactions. |
| pg_wal | Thư mục con chứa các file WAL (Write Ahead Log). |
| pg_xact | Thư mục con chứa thông tin về trạng thái commit của dữ liệu. |
| postgresql.auto.conf | File lưu trữ các thông số cấu hình được thiết lập bởi ALTER SYSTEM |
| postmaster.opts | File này chứa thông tin về các tuỳ chọn lần cuối của lệnh khởi động PostgreSQL. |
| postmaster.pid | File này tạo ra khi khởi động PostgreSQL và mất đi khi shutdown PostgreSQL. File chứa thông tin về PID của postmaster process, đường dẫn thư mục dữ liệu, thời gian khởi động, số hiệu port, đường dẫn Unix-domain socket (là trống trên môi trường Windows), giá trị hiệu lực đầu tiên chỉ định trong tham số listen_address và segment ID shared memory (tạo lúc khởi động PostgreSQL). |
Vacuum
Vacuum là gì ? Tại sao PostgreSQL lại cần có Vacuum ?
Khác với các RDBMS khác (như MySQL), khi người dùng chạy lệnh DELETE hay UPDATE, PostgreSQL không xoá dữ liệu cũ đi luôn mà chỉ đánh dấu "đó là dữ liệu đã bị xoá". Nên nếu liên tục INSERT/DELETE hoặc UPDATE dữ liệu mà không có cơ chế xoá dữ liệu dư thừa thì dung lượng ổ cứng tăng dẫn đến full.
PostgreSQL sử dụng 32 bit Transaction ID (XID) để quản lý transaction(1). Mỗi một record dữ liệu đều có thông tin về XID. Khi dữ liệu được tham chiếu PostgreSQL sử dụng thông tin XID này so sánh với XID hiện tại để đánh giá dữ liệu này có hữu hiệu không. Dữ liệu đang tham chiếu có XID lớn hơn XID hiện tại là dữ liệu không hữu hiệu. Khi sử dụng hết 32 bit XID (khoảng 4 tỷ transactions), để sử dụng tiếp XID sẽ được reset về ban đầu (0). Nếu không có cơ chế chỉnh lại XID trong data thì mỗi lần reset XID, dữ liệu hiện tại sẽ trống trơn (dữ liệu hiện tại luôn có XID lớn hơn XID đã reset (0)).
Như vậy Vacuum ra đời để giải quyết những vấn đề:
- Lấy lại dữ liệu dư thừa để tái sử dụng
- Cập nhật thông tin thống kê (statistics)
- Giải quyết vấn đề dữ liệu bị vô hiệu khi Wraparound Transaction ID
Lấy lại dữ liệu thừa
Như trên, PostgreSQL chưa xoá dữ liệu cũ khi thực hiện thao tác DELETE/UPDATE. Khi VACUUM, những dữ liệu dư thừa đó sẽ được lấy lại và vị trí dư thừa sẽ được cập nhật lại trong bảng vị trí trống (Free Space Map(FSM)). Ngoài ra những block dữ liệu đã được VACUUM sẽ được đánh dấu là đã VACUUM trên bảng khả thị (Visibility Map(VM)), khi UPDATE/DELETE dữ bảng khả thị sẽ cập nhật lại trạng thái là cần VACUUM.
Free Space Map(FSM): Mỗi bảng dữ liệu (hoặc index) tồn tại tương ứng một FSM. FSM chứa thông tin các vị trí trống trong file dữ liệu. Khi dữ liệu mới được ghi PostgreSQL sẽ nhìn vị trí trống từ FSM trước, việc này giảm thiểu truy cập trực tiếp (sinh I/O disk) vào file dữ liệu. File FSM nằm cùng vị trí với file dữ liệu và có tên = file_dữ_liệu_fsm (như ví dụ dưới).
Visibility Map(VM): Mỗi bảng dữ liệu tồn tại tương ứng một visibility map (VM). Một block dữ liệu tương ứng với 1 bit trên VM. VACUUM xem trước thông tin VM của bảng dữ liệu, và chỉ thực hiện trên những block cần được VACUUM. File VM nằm cùng vị trí với file dữ liệu và có tên = file_dữ_liệu_vm (như ví dụ dưới).
testdb=# create table testtbl(id integer);
CREATE TABLE
testdb=# insert into testtbl select generate_series(1,100);
INSERT 0 100
testdb=# delete from testtbl where id < 90;
DELETE 89
testdb=# checkpoint;
CHECKPOINT
testdb=# \! ls -l $PGDATA/base/16384/24576*
-rw------- 1 bocap staff 8192 Jun 24 18:19 /Users/bocap/Downloads/pg94/data/base/16384/24576
-rw------- 1 bocap staff 24576 Jun 24 18:19 /Users/bocap/Downloads/pg94/data/base/16384/24576_fsm
-rw------- 1 bocap staff 8192 Jun 24 18:19 /Users/bocap/Downloads/pg94/data/base/16384/24576_vm
Cập nhật lại thông tin thống kê
Một số bạn lầm tưởng rằng chỉ có chức năng ANALYZE mới cập nhật lại thông tin thống kê dùng bởi planner, nhưng thực tế VACUUM cũng cập nhật thông tin này. Cụ thể là relpages và reltuples trong system catalog pg_class. Do vậy nên có thể nói VACUUM cũng ảnh hưởng tới việc chọn plan thực thi.
postgres=# select relpages,reltuples from pg_class where relname = 'testtbl';
relpages | reltuples
----------+-----------
0 | 0
(1 row)
postgres=# insert into testtbl select generate_series(1,10),random()::text;
INSERT 0 10
postgres=# select relpages,reltuples from pg_class where relname = 'testtbl';
relpages | reltuples
----------+-----------
0 | 0
(1 row)
postgres=# vacuum testtbl;
VACUUM
postgres=# select relpages,reltuples from pg_class where relname = 'testtbl';
relpages | reltuples
----------+-----------
1 | 10
(1 row)
autovacuum
autovacuum là chức năng tự động thực thi VACUUM hoặc ANALYZE khi cần thiết. Chức năng này hoạt động khi tham số autovacuum và track_counts thiết lập là on. Cả 2 tham số này đều mặc định là on nên autovacuum sẽ tự động hoạt động khi khởi động PostgreSQL. Khi tham số autovacuum là on. Sau khi khởi động PostgreSQL tiến trình autovacuum launcher sẽ đảm nhận việc này.
BocapnoMacBook-Pro:postgres bocap$ ps -ef | grep autovacuum | grep -v grep
501 3169 3164 0 13Aug17 ?? 0:03.13 postgres: autovacuum launcher process
Tiến trình launcher cứ mỗi autovacuum_naptime sẽ kiểm tra thông tin thống kê, nếu thấy bảng nào cần thiết VACUUM hoặc ANALYZE, launcher process sẽ khởi động các worker processes để thực hiện việc VACUUM hoặc ANALYZE. Số lượng tiến trình autovacuum worker hoạt động trong cùng một thời điểm được giới hạn bởi tham số autovacuum_max_workers (mặc định là 3).
BocapnoMacBook-Pro:postgres bocap$ ps -ef | grep autovacuum | grep -v grep
501 26490 26484 0 1:14AM ?? 0:00.01 postgres: autovacuum launcher process
501 26618 26484 0 1:16AM ?? 0:00.03 postgres: autovacuum worker process postgres
Điều kiện cần thiết cho bảng được VACUUM hoặc ANALYZE bởi autovacuum như bên dưới.
VACUUM
Bảng sẽ tự động được VACUUM khi số lượng dòng bị xoá hoặc update lớn hơn: autovacuum_vacuum_scale_factor * tổng số lượng dòng + autovacuum_vacuum_threshold.
Ví dụ: số lượng dòng là 1000, thì mặc định khi số dòng bị xoá hoặc update lớn hơn 0.2*1000 + 50 = 250 bảng sẽ tự động được VACUUM
ANALYZE
Bảng sẽ tự động được ANALYZE khi số lượng dòng bị xoá hoặc update lớn hơn: autovacuum_analyze_scale_factor * tổng số lượng dòng + autovacuum_analyze_threshold.
Ví dụ: số lượng dòng là 1000, thì mặc định khi số dòng bị xoá, update hoặc insert lớn hơn 0.1*1000 + 50 = 250 bảng sẽ tự động được ANALYZE
Giám sát hoạt động autovacuum
Để biết đối tượng bảng có được VACUUM, ANALYZE hợp lý không ta có thể xem thông qua view pg_stat_all_tables.
-- ví dụ bên dưới cho thấy bảng testtbl đã được:
-- vacuum thủ công vào lúc: 2017-08-26 23:50:28
-- autovacuum vào lúc: 2017-08-27 01:16:04
-- autoanalyze vào lúc: 2017-08-27 01:16:04
postgres=# select last_vacuum,last_autovacuum,last_analyze,last_autoanalyze from pg_stat_all_tables where relid = (select oid from pg_class where relname = 'testtbl');
last_vacuum | last_autovacuum | last_analyze | last_autoanalyze
-------------------------------+-------------------------------+--------------+-------------------------------
2017-08-26 23:50:28.025241+09 | 2017-08-27 01:16:04.664297+09 | | 2017-08-27 01:16:04.665366+09
(1 row)
Ngoài ra, ta có thể theo dõi tình trạng hoạt động của autovacuum thông qua việc thiết lập tham số log_autovacuum_min_duration = 0 (log tất cả các hoạt động autovacuum).
2017-08-27 01:16:04.664 JST [26618] LOG: automatic vacuum of table "postgres.public.testtbl": index scans: 0
pages: 1276 removed, 0 remain, 0 skipped due to pins, 0 skipped frozen
tuples: 100000 removed, 0 remain, 0 are dead but not yet removable, oldest xmin: 579
buffer usage: 3851 hits, 0 misses, 0 dirtied
avg read rate: 0.000 MB/s, avg write rate: 0.000 MB/s
system usage: CPU: user: 0.02 s, system: 0.00 s, elapsed: 0.28 s
2017-08-27 01:16:04.665 JST [26618] LOG: automatic analyze of table "postgres.public.testtbl" system usage: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s
Tổng quát
Trên đây là các kiến thức nền tảng về PostgreSQL. Bài viết tuy dài nhưng có lẽ nó sẽ hữu ích với những ai mới học PostgreSQL.
Tham khảo
* KHOÁ HỌC ORACLE DATABASE A-Z ENTERPRISE trực tiếp từ tôi giúp bạn bước đầu trở thành những chuyên gia DBA, đủ kinh nghiệm đi thi chứng chỉ OA/OCP, đặc biệt là rất nhiều kinh nghiệm, bí kíp thực chiến trên các hệ thống Core tại VN chỉ sau 1 khoá học.
* CÁCH ĐĂNG KÝ: Gõ (.) hoặc để lại số điện thoại hoặc inbox https://m.me/tranvanbinh.vn hoặc Hotline/Zalo 090.29.12.888
* Chi tiết tham khảo:
https://bit.ly/oaz_w
=============================
KẾT NỐI VỚI CHUYÊN GIA TRẦN VĂN BÌNH:
📧 Mail: binhoracle@gmail.com
☎️ Mobile/Zalo: 0902912888
👨 Facebook: https://www.facebook.com/BinhOracleMaster
👨 Inbox Messenger: https://m.me/101036604657441 (profile)
👨 Fanpage: https://www.facebook.com/tranvanbinh.vn
👨 Inbox Fanpage: https://m.me/tranvanbinh.vn
👨👩 Group FB: https://www.facebook.com/groups/DBAVietNam
👨 Website: https://www.tranvanbinh.vn
👨 Blogger: https://tranvanbinhmaster.blogspot.com
🎬 Youtube: https://www.youtube.com/@binhguru
👨 Tiktok: https://www.tiktok.com/@binhguru
👨 Linkin: https://www.linkedin.com/in/binhoracle
👨 Twitter: https://twitter.com/binhguru
👨 Podcast: https://www.podbean.com/pu/pbblog-eskre-5f82d6
👨 Địa chỉ: Tòa nhà Sun Square - 21 Lê Đức Thọ - Phường Mỹ Đình 1 - Quận Nam Từ Liêm - TP.Hà Nội
=============================



